Lab 3: Dataform
caution
You are viewing this lab from the handbook. This lab is meant to be loaded as Cloud Shell tutorial. Please see the labs section on how to do so.
During this lab, you gather user feedback to assess the impact of model adjustments on real-world use (prediction), ensuring that our fraud detection system effectively balances accuracy with user satisfaction.
- Use Dataform, BigQuery and Gemini to Perform sentiment analysis of customer feedback.
Dataform
Dataform is a fully managed service that helps data teams build, version control, and orchestrate SQL workflows in BigQuery. It provides an end-to-end experience for data transformation, including:
- Table definition: Dataform provides a central repository for managing table definitions, column descriptions, and data quality assertions. This makes it easy to keep track of your data schema and ensure that your data is consistent and reliable.
- Dependency management: Dataform automatically manages the dependencies between your tables, ensuring that they are always processed in the correct order. This simplifies the development and maintenance of complex data pipelines.
- Orchestration: Dataform orchestrates the execution of your SQL workflows, taking care of all the operational overhead. This frees you up to focus on developing and refining your data pipelines.
Dataform is built on top of Dataform Core, an open source SQL-based language for managing data transformations. Dataform Core provides a variety of features that make it easy to develop and maintain data pipelines, including:
- Incremental updates: Dataform Core can incrementally update your tables, only processing the data that has changed since the last update.
- Slowly changing dimensions: Dataform Core provides built-in support for slowly changing dimensions, which are a common type of data in data warehouses.
- Reusable code: Dataform Core allows you to write reusable code in JavaScript, which can be used to implement complex data transformations and workflows.
Dataform is integrated with a variety of other Google Cloud services, including GitHub, GitLab, Cloud Composer, and Workflows. This makes it easy to integrate Dataform with your existing development and orchestration workflows.
Use Cases for Dataform
Dataform can be used for a variety of use cases, including:
- Data Warehousing: Dataform can be used to build and maintain data warehouses that are scalable and reliable.
- Data Engineering: Dataform can be used to develop and maintain data pipelines that transform and load data into data warehouses.
- Data Analytics: Dataform can be used to develop and maintain data pipelines that prepare data for analysis.
- Machine Learning: Dataform can be used to develop and maintain data pipelines that prepare data for machine learning models.
Create a Dataform Pipeline
First step in implementing a pipeline in Dataform is to set up a repository and a development environment. Detailed quickstart and instructions can be found here.
Create a Repository in Dataform
Go to Dataform (part of the BigQuery console).
-
Click on
+ CREATE REPOSITORY -
Use the following values when creating the repository:
Repository ID:
hackathon-repository
Region:us-central1
Service Account:Default Dataform service account -
Set actAs permission checks to
Don't enforce -
And click on
CREATE The dataform service account you see on your screen should be
service-<PROJECT_NUMBER>@gcp-sa-dataform.iam.gserviceaccount.com. We will need it later. -
Select
Grant all required roles for the service-account to execute queries in Dataform
Next, click
Create a Dataform Workspace
You should now be in the
First, click
In the Create development workspace window, do the following:
-
In the
Workspace ID field, enterhackathon--workspaceor any other name you like. -
Click
CREATE -
The development workspace page appears.
-
Click on the newly created
hackathon--workspace -
Click
Initialize workspace
Adjust workflow settings
We will now set up our custom workflow.
-
Edit the
workflow_settings.yamlfile : -
Replace
defaultDatasetvalue withml_datasets -
Make sure
defaultProjectvalue is<PROJECT_ID> -
Click on
INSTALL PACKAGES only once. You should see a message at the bottom of the page:Package installation succeeded
Next, let’s create several workflow files.
-
Delete the following files from the
*definitions folder:first_view.sqlxsecond_view.sqlx -
Within
*definitions create a new directory calledmodels:

-
Click on
modelsdirectory and create 2 new filescreate_dataset.sqlxllm_model_connection.sqlxExample:
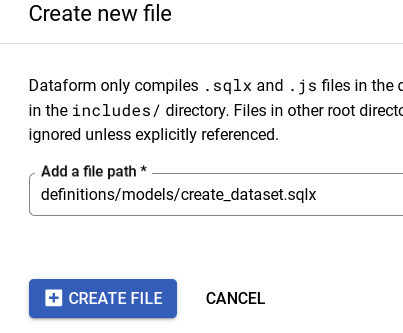
-
Copy the contents to each of those files:
-
Click on
*definitions and create 3 new files:mview_ulb_fraud_detection.sqlxsentiment_inference.sqlxulb_fraud_detection.sqlx
Example:
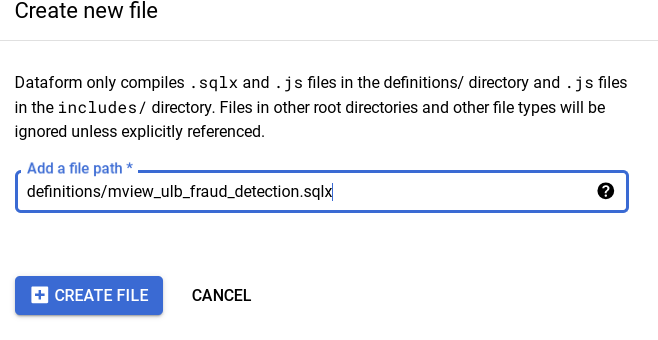
-
Copy the contents to each of those files:
-
Set the
databasevalue to your project ID<PROJECT_ID>value inulb_fraud_detection.sqlxfile:
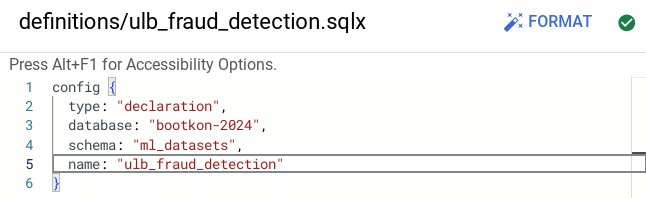
- In
llm_model_connection.sqlx, replace theus.llm-connectionconnection with the connection name you have created in LAB 2 during the BigLake section. If you have followed the steps in LAB 2, the connected name should beus.fraud-transactions-conn
Notice the usage of $ref in line 11, of definitions/mview_ulb_fraud_detection.sqlx. The advantages of using $ref in Dataform are
- Automatic Reference Management: Ensures correct fully-qualified names for tables and views, avoiding hardcoding and simplifying environment configuration.
- Dependency Tracking: Builds a dependency graph, ensuring correct creation order and automatic updates when referenced tables change.
- Enhanced Maintainability: Supports modular and reusable SQL scripts, making the codebase easier to maintain and less error-prone.
Execute Dataform workflows
Run the dataset creation by Tag. Tag allow you to just execute parts of the workflows and not the entire workflow.
Note: If you have previously granted all required roles for the service account service-<PROJECT_NUMBER>@gcp-sa-dataform.iam.gserviceaccount.com then you can skip step 1-5
-
Click on
Start execution >Tags >dataset_ulb_fraud_detection_llm At the top where it says “Authentication”, make sure you select
Execute with selected service accountand choose your dataform service account:service-<PROJECT_NUMBER>@gcp-sa-dataform.iam.gserviceaccount.comThen click
Start execution -
Click on
DETAILS Notice the Access Denied error on BigQuery for the dataform service account
service-<PROJECT_NUMBER>@gcp-sa-dataform.iam.gserviceaccount.com. If did not receive an error, you can skip step 3-6. -
Go to IAM & Admin
-
Click on
GRANT ACCESS and grantBigQuery Data Editor , BigQuery Job User and BigQuery Connection Userto the principalservice-<PROJECT_NUMBER>@gcp-sa-dataform.iam.gserviceaccount.com. -
Click on
SAVE
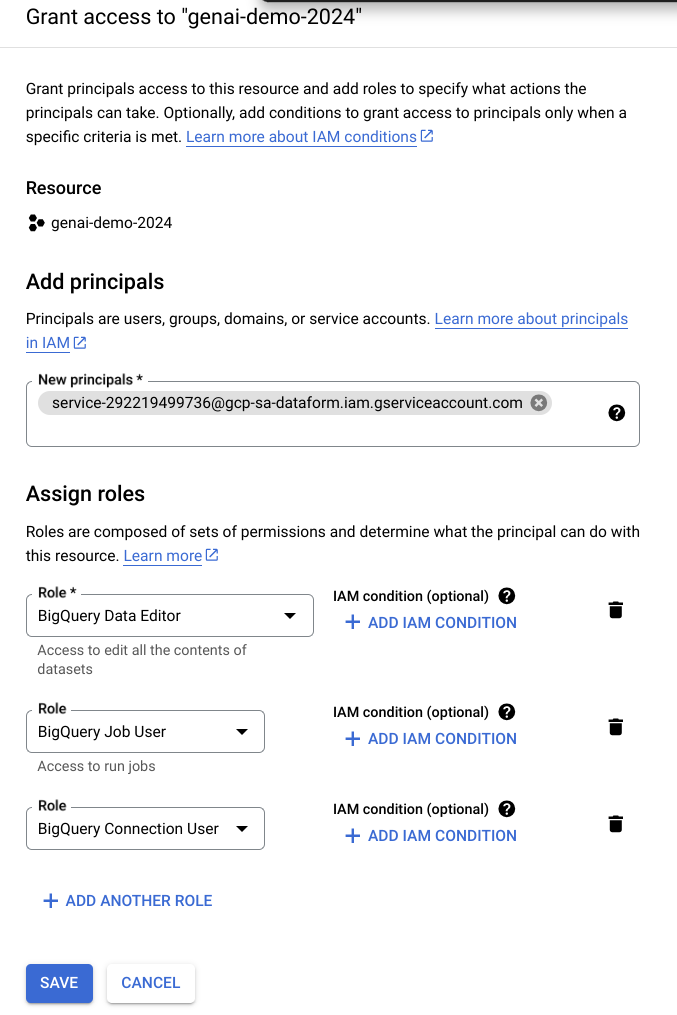
Note: If you encounter a policy update screen, just click on update.
-
Go back to Dataform within in BigQuery, and retry
Start execution >Tags >dataset_ulb_fraud_detection_llm At the top where it says “Authentication”, make sure you select
Execute with selected service accountand choose your dataform service account:service-<PROJECT_NUMBER>@gcp-sa-dataform.iam.gserviceaccount.comThen click
Start execution
Notice the execution status. It should be a success. -
Lastly, go to Compiled graph and explore it. Go to Dataform>
hackathon-repository >hackathon--workspace>COMPILED GRAPH
Execute the workspace workflow
For the sentiment inference step to succeed, you need to grant the external connection service account the Vertex AI user privilege. More details can be found in this link.
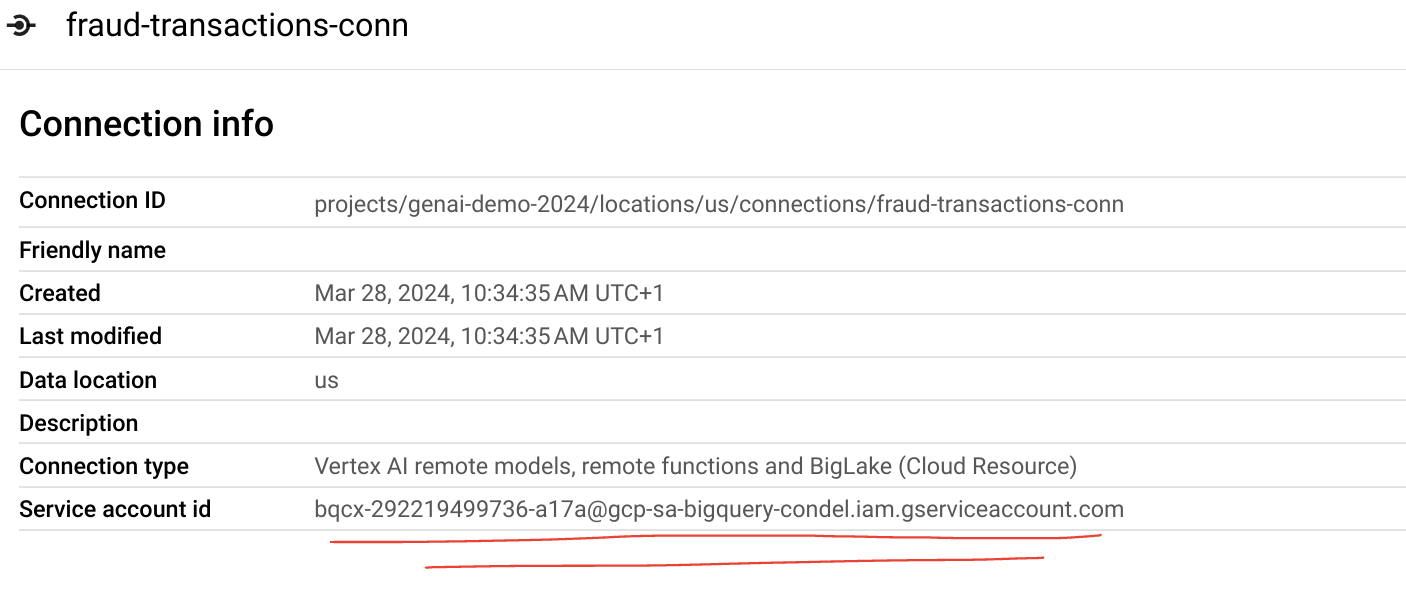
- You can find the service account ID under BigQuery Studio >
Explorer ><PROJECT_ID>>Connections >fraud-transactions-conn
-
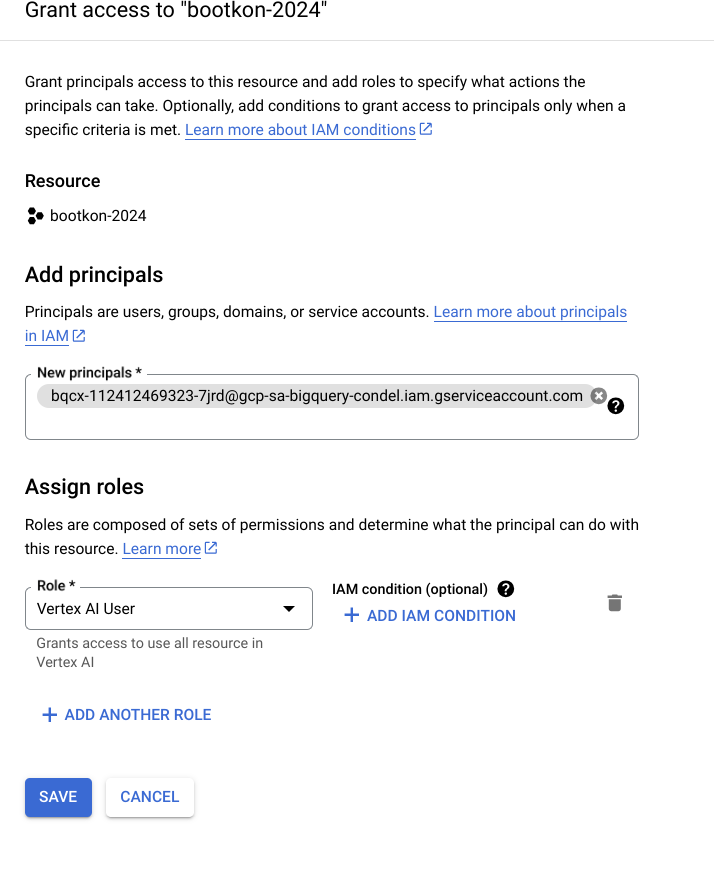
Take note of the service account and grant it the
Vertex AI Userrole in IAM.
-
Back in your Dataform workspace, click
Start execution from the top menu, thenExecute Actions At the top where it says “Authentication”, make sure you select
Execute with selected service accountand choose your dataform service account:service-<PROJECT_NUMBER>@gcp-sa-dataform.iam.gserviceaccount.com -
Click on
ALL ACTIONS Tab followed by choosingStart execution -
Check the execution status. It should be a success.
-
Verify the new table
sentiment_inferencein theml_datasetsdataset in BigQuery and query the BigQuery table content (At this point you should be familiar with running BigQuery SQL)SELECT distinct ml_generate_text_llm_result, prompt, Feedback FROM `ml_datasets.sentiment_inference` LIMIT 10;[Max 2 minutes] Discuss the table results within your team group.
-
Before moving to the challenge section of the lab, go back to the
Code section of the Dataform workspace. At the top of the “Files” section on the left, clickCommit X Changes (X should be about 7), add a commit message like, “Bootkon lab 3”, then clickCommit all files and thenPush to default branch You should now have the message: Workspace is up to date
Challenge section: production, scheduling and automation
Automate and schedule the compilation and execution of the pipeline. This is done using release configurations and workflow configurations.
Release Configurations:
Release configurations allow you to compile your pipeline code at specific intervals that suit your use case. You can define:
-
Branch, Tag, or Commit SHA: Specify which version of your code to use.
-
Frequency: Set how often the compilation should occur, such as daily or weekly.
-
Compilation Overrides: Use settings for testing and development, such as running the pipeline in an isolated project or dataset/table.
Common practice includes setting up release configurations for both test and production environments. For more information, refer to the release configuration documentation.
Workflow Configurations
To execute a pipeline based on your specifications and code structure, you need to set up a workflow configuration. This acts as a scheduler where you define:
-
Release Configuration: Choose the release configuration to use.
-
Frequency: Set how often the pipeline should run.
-
Actions to Execute: Specify what actions to perform during each run.
The pipeline will run at the defined frequency using the compiled code from the specified release configuration. For more information, refer to the workflow configurations documentation.
[TASK] Challenge : Take up to 10 minutes to Setup a Daily Frequency Execution of the Workflow
Goal: Set up a daily schedule to automate and execute the workflow you created.
- Automate and schedule the pipeline’s compilation and execution.
- Define release configurations for one production environment (optionally: you can create another one for dev environment)
- Set up workflow configurations to schedule pipeline execution (use dataform service account).
- Set up a 3 minute frequency execution of the workflow you have created.
Note: If you are stuck and cannot figure out how to proceed after a few minutes, ask your team captain.
Success
🎉 Congratulations! 🚀
You’ve just finished the lab, and wow, what a ride! You dove headfirst into the world of Dataform, BigQuery, and Gemini, building a sentiment analysis pipeline from scratch. Remember all those setup steps? Repository, workspace, connections…it’s a blur now, but you nailed it.
Those pesky “Access Denied” errors? Conquered. The pipeline? Purring like a data-driven kitten, churning out sentiment scores like nobody’s business. And the best part? You automated the whole thing! Scheduled executions? Check. You’re a data pipeline master. Bring on the next challenge – you’ve got this! 🚀